
- ✅ 概要
- ✅ 各アーキテクチャパターンの詳細解説
- 🔍 パターン1: SQS -> Lambda -> ECS (API) -> RDS (キュー) <- ECS (Worker)
- 🔍 パターン2: SQS <- ECS(Worker) -> RDS (キュー) <- ECS (Worker)
- 🔍 パターン3: SQS -> Lambda -> DynamoDB <- ECS (メイン処理)
- 🔍 パターン4: SQS -> Lambda -> DynamoDB -> Lambda(DynamoDB Stream) -> メイン処理
- 🔍 パターン5: SQS <– ECS (Worker) -> DynamoDB (キュー) <- ECS (Worker)
- 🔍 パターン6: SQS -> Lambda -> DynamoDB -> Lambda -> Step Functions -> ECS (メイン処理)
- ✅ 3. 考察:最適な選択肢と改善案
- ✅ まとめ
✅ 概要
実務でよくあるSQSとECSの組み合わせでさまざまなアーキテクチャを考えれるので、今回まとめてみました!!!
AWSのメッセージキューイングサービスであるSQS(Simple Queue Service)とコンテナオーケストレーションサービスであるECS(Elastic Container Service)は、非同期処理やバッチ処理システムを構築する上で強力な組み合わせです。
しかし、LambdaやDynamoDBといった他のサービスをどのように組み込むかによって、アーキテクチャの特性(コスト、スケーラビリティ、複雑性、運用性)は大きく変わります。
最適なアーキテクチャは、システムの要件、処理内容、運用体制によって異なります。この記事では、SQSとECSを中心とした代表的なアーキテクチャパターンを6つ取り上げ、それぞれの構成、メリット、デメリット、そして具体的な適用シナリオについて、より深く掘り下げて解説します。
✅ 各アーキテクチャパターンの詳細解説
🔍 パターン1: SQS -> Lambda -> ECS (API) -> RDS (キュー) <- ECS (Worker)
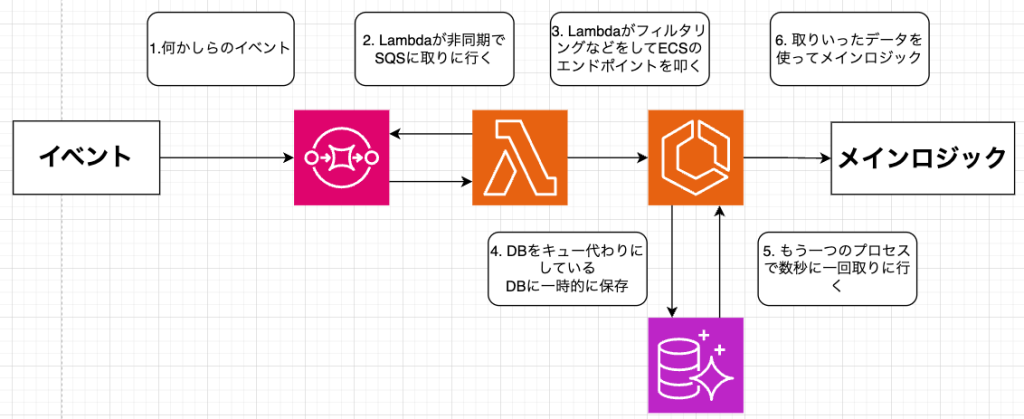
📌 構成概要
このパターンでは、SQSにエンキューされたメッセージをLambda関数がトリガーとして受け取ります。Lambdaはメッセージの内容に基づいて軽量な前処理(バリデーション、フィルタリング、データ変換など) を実行します。処理対象と判断された場合、Lambdaは既にECS上で稼働しているアプリケーション(例: APIサーバーとして実装されたコンテナ)に対してREST APIを呼び出し、データを渡します。
ECS内では、2つの主要なプロセス(またはコンテナ群) が稼働していることを想定します:
- API受付プロセス: LambdaからのREST APIコールを受け付け、渡されたデータをRDS内の特定のテーブルに一時データとして書き込みます。このRDSテーブルが事実上の「キュー」として機能します。
- メインロジック実行プロセス (Worker): 数秒ごとなど定期的にRDSのキューテーブルをポーリングし、未処理のデータを取得します。取得したデータに基づいて、比較的重い、または長時間実行される可能性のあるメインロジックを実行し、処理結果をRDSの他のテーブルに反映したりします。
この構成では、Lambdaはあくまでフィルター兼ディスパッチャーであり、ECSのAPIプロセスがデータの一次受け付けとキューイング(RDS利用)、ECSのWorkerプロセスが実際の非同期処理を担当します。
💡 メリット
- 迅速なフィルタリングと負荷軽減: Lambdaによる前処理で、不正データや不要なリクエストがECSのAPIやRDSキューに到達するのを防ぎ、リソース効率を高めます。
- サーバーレスの恩恵 (部分的): メッセージ処理の入口であるLambdaは自動スケールし、アイドル時のコスト効率が良いです(非プロビジョンド時)。
- 関心の分離: 前処理(Lambda)、API受付(ECSプロセスA)、メインロジック(ECSプロセスB)と責務が明確に分離され、開発・保守がしやすくなります。
- ECSタスク起動オーバーヘッドなし: RunTask を毎回呼び出すわけではないため、コンテナの起動時間を待つ必要がなく、LambdaからECSへの連携は(ネットワーク遅延を除けば)比較的速やかに行えます。
⚠️ デメリット
- RDSキューイングとポーリングの負担: RDSをキューとして利用し、ECS Workerが高頻度でポーリングすることは、RDSへの大きな負荷となり、パフォーマンスボトルネックやコスト増加(I/O等)の主要因となります。テーブル設計(インデックス等)やロック競合に細心の注意が必要です。この構成における最大の懸念点と言えます。
- ECSの常時稼働コスト: API受付プロセスとWorkerプロセスを実行するECSタスクは常に稼働している必要があり、アイドル時でもコストが発生します。
- 実装の複雑性: ECS内にAPI受付とWorkerという2つの異なる役割を持つプロセス(または別々のサービス)を構築・管理する必要があります。また、RDSをキューとして使うための状態管理(処理中、完了、失敗など)の実装も必要です。
- Lambda->ECS API連携: LambdaからECS APIへのネットワーク呼び出しにおけるエラーハンドリング、認証、タイムアウト管理などが必要です。
- 状態追跡の複雑性: LambdaがAPIを呼び出した後、そのデータが最終的にWorkerプロセスで正常に処理されたかを追跡・監視する仕組みが必要になる場合があります。
🔍 適用シナリオ
- 入力データの厳密な事前フィルタリングが必要で、かつメイン処理は既存のECSアプリケーション基盤で行いたい場合。
- SQSのメッセージ流量に応じてスケールする入口(Lambda)を持ちつつ、後続の重い処理はECSで安定的に実行したい場合(ただしRDSポーリングの性能限界は考慮必須)。
- API Gatewayなど、他のサービスからのリクエストも同じECS APIエンドポイントで受け付け、非同期処理に流したい場合。
- RDSをキューとして使うことのデメリットを許容できる、あるいは特定の理由(既存資産など)でRDSを使う必要がある場合。 (一般的にはSQSやDynamoDBをキューとして使う方が推奨されます)
- ※コンテナ構成で複数プロセスを持たせるということ自体アンチパターンかもしません。(個人的にはあまり推奨しません。)
🔍 パターン2: SQS <- ECS(Worker) -> RDS (キュー) <- ECS (Worker)
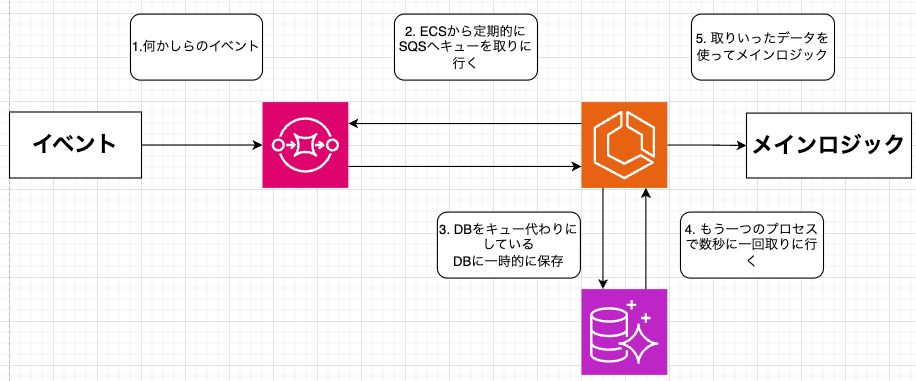
📌 構成概要
SQSキューをECSサービスが直接監視し、メッセージを取得してメインロジックを実行します。数秒ごとにSQSを見に行き、RDSに保存するプロセスと保存したRDS上のデータを取りに行きメインプロセスを実行する二つのプロセスが必要になります。
ECSサービスのAuto ScalingとSQSキューの深さを連携させ、負荷に応じてタスク数を自動調整します。ECSタスクはSQSからメッセージを取得し、RDSに必要なデータの読み書きを行って処理を完了させます。Lambdaは介在しません。
💡 メリット
- アーキテクチャのシンプルさ: コンポーネントが少なく、構築・運用が比較的容易です。
- コスト効率(特定条件下で): Lambda関連コストが不要。定常負荷や長時間タスクが多い場合に有利なことがあります。
- 技術スタックの統一: コンピューティングがECSに統一され、開発・運用効率が良い場合があります。
- 長時間処理への適合: Lambdaの実行時間制限がなく、長時間のバッチ処理に適しています。
⚠️ デメリット
- RDSポーリングの負担: パターン1同様、ECSによるRDSポーリングは非効率的です。
- スケーリングの応答性: ECS Auto ScalingはLambdaほど即時的ではなく、数分のタイムラグが発生します。急なスパイクへの追従性は劣ります。
- メッセージフィルタリングの不在: 不正メッセージ等もECSが一旦受け取る必要があり、リソース効率が悪化する可能性があります。
- アイドル時のコスト: メッセージが無くても最低限のECSタスクが起動し続けるため、コストが発生します。
- コンテナ構成で複数のプロセスは運用上よくない。
🔍 適用シナリオ
- シンプルな非同期タスク処理(定型処理+DB保存)。
- コスト最適化が重要な定常負荷システムで、Lambda導入メリットが少ない場合。
- 既存のECS運用基盤を最大限活用したい場合。
- 実行時間が15分を超える可能性のある長時間バッチ処理。
🔍 パターン3: SQS -> Lambda -> DynamoDB <- ECS (メイン処理)

📌 構成概要
SQSメッセージをLambdaが受け取り、処理に必要な中間データやジョブの状態をDynamoDBに保存します。ECSタスクは、DynamoDBテーブルを定期的にポーリングするか、DynamoDB StreamsとLambdaを介してイベント駆動でトリガーされ、DynamoDBから処理対象データを取得してメインロジックを実行します。DynamoDBが一時的なデータストアやジョブキューとして機能します。
💡 メリット
- 高いスケーラビリティと柔軟性: DynamoDBがバッファとなり、LambdaとECSの処理速度差を吸収し、疎結合性を高めます。
- 状態管理の容易化: DynamoDBにジョブ状態(待機中、処理中等)を保存することで、複雑な処理の状態管理が容易になります。
- 楽観的ロックによる同時実行制御: DynamoDBの機能で、複数ECSタスクによる同一ジョブの重複処理を防止できます。
- データ永続化と追跡: 処理履歴の追跡や再処理が容易になります(TTL設定も可能)。
⚠️ デメリット
- DynamoDBコスト: WCU/RCU、ストレージ、オプション機能によりコストが増加する可能性があります。キャパシティ管理が重要です。
- 実装の複雑性: DynamoDBへの書き込み/読み込み、状態管理、楽観ロック等の実装が必要で、複雑性が増します。
- 結果整合性の考慮: DynamoDBの結果整合性を理解し、必要なら強い整合性リード(コスト増)を検討する必要があります。
- ポーリングによる遅延/コスト(ECSポーリング時): DynamoDBポーリングは遅延やコスト要因になり得ます。(Stream利用で改善可能)
- Lambdaの起動コスト: パターン1同様、Lambdaのコストがかかります。
🔍 適用シナリオ
- ジョブキューシステム(状態管理が必要なタスク)。
- ファンアウト/ファンインパターン(1メッセージから複数サブタスク生成、状態管理)。
- 冪等性が厳密に求められる処理(DynamoDBで処理済みか確認)。
- 大量データを一時的にバッファリングし、ECSが自身のペースで処理したい場合。
🔍 パターン4: SQS -> Lambda -> DynamoDB -> Lambda(DynamoDB Stream) -> メイン処理

📌 構成概要
これは完全サーバーレスを目指すパターンです。SQSメッセージを最初のLambdaが受け取り、処理(または状態登録)を行い、結果や次のステップの情報をDynamoDBに保存します。DynamoDBテーブルへの書き込みイベント(Insert/Update)をDynamoDB Streamsで検知し、それをトリガーとして後段のLambda関数が起動します。この後段のLambdaが、メインロジックを実行します。ECSは使用しません。
💡 メリット
- 完全サーバーレス: インフラ管理が不要で、スケーラビリティが非常に高い構成です。メンテナンス負担が最小限になります。
- コスト効率(低〜中頻度処理): アイドル時はコストがほぼ発生せず、処理量に応じた従量課金のため、処理頻度が低い場合にコストを抑えられます。
- イベント駆動: DynamoDB Streamsにより、データ変更を起点とした効率的なイベント駆動処理が可能です。
- DynamoDB機能活用: トランザクション、TTL、グローバルテーブルなど、DynamoDBの機能を最大限活用できます。
⚠️ デメリット
- Lambdaコスト(高頻度処理): 処理頻度が非常に高い場合、Lambdaの実行回数が増え、コストがECSより高くなる可能性があります。
- DynamoDB書き込みコスト: 高頻度の書き込みはDynamoDBコストも増加させます。
- Lambdaの制約: 実行時間(15分)、メモリ/CPU、一時ストレージ、コールドスタートといったLambda固有の制約を受けます。複雑・長時間のメインロジックには向きません。
- 楽観ロックの必要性: 同一アイテムへの同時更新が発生しうる場合、楽観ロックの実装が必要になることがあります。
- 複雑なワークフロー非対応: Step Functionsを使わないため、複雑な分岐や状態管理、エラーハンドリングは自前で実装する必要があります。
🔍 適用シナリオ
- 完全サーバーレス構成を最優先する場合。
- 運用負荷を極限まで削減したいシステム。
- メインロジックが比較的軽量(Lambdaの制限内)で、ステートレスまたはDynamoDBで状態管理可能な処理。
- リアルタイムに近いイベント処理(例: IoTデータの処理、ユーザーアクションに基づく処理)。
- 開発速度を重視し、インフラ管理を避けたいスタートアップや新規プロジェクト。
🔍 パターン5: SQS <– ECS (Worker) -> DynamoDB (キュー) <- ECS (Worker)

📌 構成概要
パターン1の派生形とも言えます。SQSからメッセージを直接ECSが受け取りますが、データストアとしてRDSだけでなくDynamoDBも選択肢に入ります。ECSタスクは、SQSメッセージに基づいて、DynamoDBに対してポーリングを行うか、あるいはECSタスク内でデータストアのイベント(例: DynamoDB Streams)を処理するライブラリやロジックを実装し、メインロジックを実行します。Lambdaは使用しません。
💡 メリット
- Lambda排除によるシンプル化(一部): Lambdaコンポーネントがなく、ECSに処理を集約できます。
- データストア選択の柔軟性: 要件に応じてRDSまたはDynamoDBを選択できます。DynamoDBを採用すればスケーラビリティを高められます。
- ECS内での柔軟な実装: ポーリング間隔の調整や、イベント処理ライブラリ(例: Kinesis Client Library for DynamoDB Streams)の利用など、ECSコンテナ内で比較的自由な実装が可能です。
⚠️ デメリット
- ECSインスタンス/タスク管理の複雑性: 適切なインスタンスタイプ/タスク数の選定、Auto Scaling設定、OS/ミドルウェア管理など、サーバーレスでない運用の手間がかかります。
- サーバー管理コスト: ECS (EC2起動タイプ) や Fargate のコストが発生し、アイドル時もコストがかかります。
- ポーリング非効率性(ポーリング実装時): DynamoDBへのポーリングは依然として非効率な場合があります。
- イベント処理実装の複雑性(イベント管理実装時): ECS内でDynamoDB Streams等を処理する場合、KCLのようなライブラリのセットアップや状態管理(シャーディング等)が必要となり、実装が複雑になる可能性があります。
- スケーリング応答性: パターン2同様、Lambdaほど即応性のあるスケーリングは期待できません。
🔍 適用シナリオ
- Lambdaを使わずに、ECSのコンピューティングパワーや柔軟性を最大限活用したい場合。
- データストアとしてDynamoDBのスケーラビリティが必要だが、処理ロジックは既存のコンテナ資産を活用したい、またはLambdaの制約を受けたくない場合。
- ECS内でのポーリングやイベント処理の実装・運用ノウハウがある場合。
- パターン2ではRDSがボトルネックになるが、Lambdaを導入したくない場合の代替案。
🔍 パターン6: SQS -> Lambda -> DynamoDB -> Lambda -> Step Functions -> ECS (メイン処理)
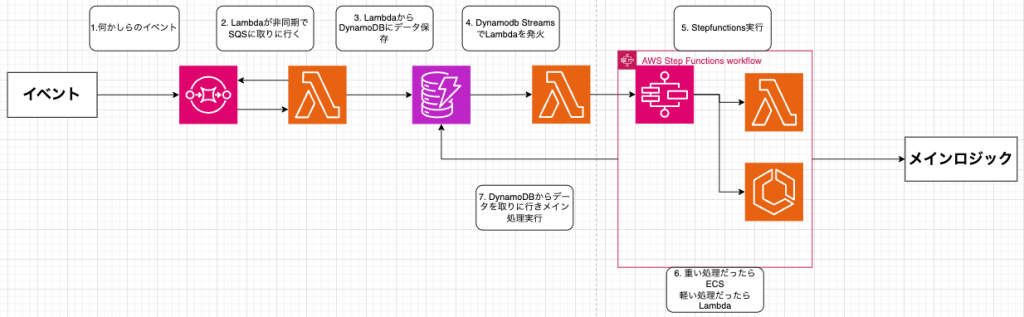
📌 構成概要
複雑なワークフローや状態遷移を伴う処理のための高度なパターンです。SQSメッセージをLambdaが受け取り、初期処理後、DynamoDBに情報を保存し、AWS Step Functionsのステートマシン実行を開始します。Step Functionsが定義されたワークフローに従い、Lambda関数やECSタスク(RunTask等で呼び出し)を順次/並行実行し、状態遷移を管理します。メインロジックの重い部分は主にECSが担当しますが、ワークフロー内の軽量なステップはLambdaが担当することもあります。
💡 メリット
- 複雑なワークフローの可視化と管理: Step Functionsにより、分岐、並列処理、エラーハンドリング、リトライを含む複雑なフローを容易に実装・管理・可視化できます。
- 堅牢なエラーハンドリングとリトライ: Step Functions組み込みの機構により、ワークフローの耐障害性が向上します。
- サーバーレスとコンテナの連携強化: LambdaとECSをオーケストレーターを通じてシームレスに連携させ、実行履歴も追跡可能です。
- 状態管理の簡素化(ワークフローレベル): Step Functionsが状態遷移を管理するため、開発者はタスク実装に集中できます。
⚠️ デメリット
- 最高レベルの複雑性: コンポーネントが多く、Step Functions(ASL)の学習コストも必要。設計・実装・テスト・デバッグの難易度が高いです。
- Step Functionsコスト: 状態遷移回数に応じた課金があり、高頻度/多ステップのワークフローではコストが増加します。(Standard/Express Workflowの選択が重要)
- デバッグの難しさ: 分散システムのため、問題特定には各種ログやX-Ray等を用いたトレーシングが不可欠です。
- Lambda/ECS起動オーバーヘッド: 各ステップでのLambdaコールドスタートやECSタスク起動 (RunTask) には時間がかかる場合があります。
🔍 適用シナリオ
- 多段階ETLパイプライン(抽出、複数変換、ロード)。
- ビジネスプロセスオートメーション(注文処理、承認ワークフロー等)。
- メディア処理や機械学習パイプライン(エンコード、分析、通知等)。
- インシデント対応自動化ワークフロー。
- 人間の承認や長時間待機を含む可能性があるワークフロー(Callbackパターン)。
✅ 3. 考察:最適な選択肢と改善案
これら6つのパターンを踏まえ、どのアーキテクチャを選択すべきか、また既存の構成をどう改善できるかのヒントを以下に示します。
📊 最適な選択肢の提案(要件別)
- 完全サーバーレス構成を最優先する場合:
- パターン4 (SQS -> Lambda -> DynamoDB -> Lambda(Stream)) が最適です。運用負荷が最小限で、スケーラビリティも非常に高いですが、Lambdaの制約(実行時間、リソース)と、高頻度処理時のコストに注意が必要です。メインロジックがLambdaで実行可能であることが前提です。
- シンプルな構成を求め、ECSメインで処理したい場合:
- パターン2 (SQS -> ECS -> RDS) は最もシンプルですが、RDSポーリングの非効率性が課題です。
- パターン3 (SQS -> Lambda -> DynamoDB -> ECS) は、DynamoDBでデカップリングと状態管理を行えますが、実装複雑性とコストが増します。Lambdaによる前処理が有効な場合に検討価値があります。
- パターン5 (SQS -> ECS -> DynamoDB) はLambdaを排除しつつDynamoDBの利用も可能ですが、ECS内でのポーリング/イベント処理の実装・運用が必要です。
- 状態管理や複雑なワークフローが必要な大規模処理:
- パターン6 (SQS -> Lambda -> DynamoDB -> lambda -> Step Functions -> ECS) が最適です。Step Functionsによる強力なワークフロー管理とエラーハンドリングが魅力ですが、複雑性とコストは最も高くなります。
- よりシンプルな状態管理でよければ パターン3 (SQS -> Lambda -> DynamoDB -> ECS) も候補になりますが、ワークフロー制御は自前実装が必要です。
- コストと運用負荷を最重視する場合:
- 処理頻度が低いなら パターン4 (完全サーバーレス) が有利な場合があります。
- 定常的な負荷があり、構成シンプルさを優先するなら パターン2、ただしRDSポーリングの課題があります。
- サーバーレスのメリットを部分的に取り入れたいなら パターン1 や パターン3 も候補ですが、LambdaやDynamoDBのコストが発生します。
🚀 改善案
どのパターンを選択するにしても、以下の点で改善や最適化が可能です。
- RDSポーリングの回避/最適化:
- 可能であれば、イベント駆動型アプローチ(例: DBトリガー -> Lambda -> SQS、あるいはCDC(Change Data Capture)ツール -> SQS)を検討し、ポーリングを避けます。
- ポーリングが避けられない場合、ポーリング間隔の最適化、クエリの効率化(インデックス等)、リードレプリカの活用を検討します。
- DynamoDBの利用最適化:
- 単なるキューとして使うだけでなく、状態管理、冪等性チェック、楽観ロックなど、より高度な目的に活用します。
- TTL (Time To Live) を設定し、不要になったアイテム(処理済みジョブなど)を自動削除することで、ストレージコストと管理の手間を削減します。
- ワークロードに合わせてオンデマンドキャパシティとプロビジョンドキャパシティを適切に選択・調整します。
- ECSのスケール管理:
- SQSキューの深さ (ApproximateNumberOfMessagesVisible) に基づくECS Auto Scalingは基本ですが、より応答性の高いスケーリングが必要な場合、カスタムメトリクスや Lambda関数によるECSサービスの動的なスケール調整(例: UpdateService APIでDesiredCountを変更)も検討できます。
- Fargate を利用すれば、サーバー管理の手間を削減できます(ただしコストはEC2起動タイプより高くなる傾向)。
- エラーハンドリングとリトライ:
- SQSのデッドレターキュー(DLQ) を設定し、処理に失敗したメッセージを隔離・調査できるようにします。
- LambdaやECSアプリケーション内で適切なリトライロジック(エクスポネンシャルバックオフ等)を実装します。
- パターン6ではStep Functionsの強力なエラーハンドリング/リトライ機能を活用します。
- コストモニタリングと最適化:
- AWS Cost ExplorerやCloudWatchメトリクスで、Lambda、ECS、DynamoDB、Step Functions、データ転送などのコストを定期的に監視し、ボトルネックや無駄を特定して最適化します。
✅ まとめ
SQSとECSを組み合わせたアーキテクチャは、非同期処理システムの強力な基盤となりますが、その具体的な構成はシステムの要件によって大きく異なります。Lambda、DynamoDB、Step Functionsといったサービスをどう組み込むかで、スケーラビリティ、コスト、運用負荷、実装の複雑性のトレードオフが変わってきます。
今回解説した6つのパターン:
- SQS -> Lambda -> ECS -> RDS: 前処理分離型
- SQS -> ECS -> RDS: シンプルECS中心型
- SQS -> Lambda -> DynamoDB -> ECS: DynamoDB活用型
- SQS -> Lambda -> DynamoDB -> Lambda(Stream): 完全サーバーレス型
- SQS -> ECS -> DynamoDB: Lambda排除・ECS柔軟型
- SQS -> Lambda -> DynamoDB -> Step Functions -> ECS: ワークフロー管理型
いかがでしたでしょうか!本当にユースケースによって構成を合わせた方が良いかと!
これらの特性を理解し、ご自身のプロジェクトの要件(処理内容、データ特性、スケーラビリティ要求、予算、運用体制など)と照らし合わせて最適なアーキテクチャの検討を!
